Agile Data Process
Martin Magdinier | 24 June 2015
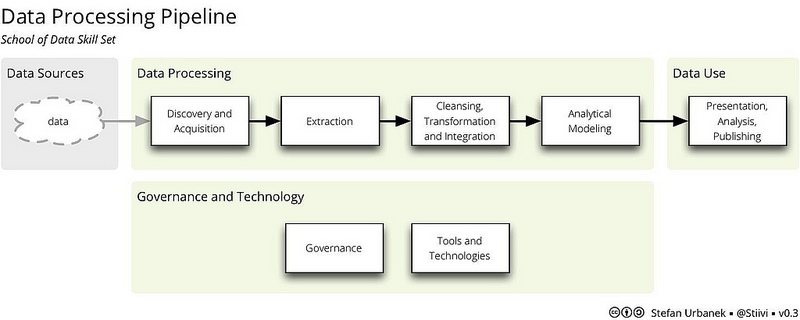
 Stefan Urbanek when laying the foundation for the school of data program at the Open Knowledge, presented the following Data Processing Pipeline going from:
Stefan Urbanek when laying the foundation for the school of data program at the Open Knowledge, presented the following Data Processing Pipeline going from:
- Data discovery and acquisition, to
- Data extraction,
- Cleansing, transformation and integration,
- Analytical modelling, and
- Presentation, analysis and publishing.
For anyone working with data regularly, it is common practice to spend up to 80% of their time in the Cleansing, Transformation and Integration part (see KDnuggets poll – NYT article). In today’s traditional data quality and integration model, that includes: data normalization; duplicate removal; pivoting, joining, and splitting data, and it relies on custom scripts managed by IT or is done by the domain expert user in a spreadsheet.
However, this model is being disrupted by the increase in data variety (the type of format and sources), volume (size of data set) and velocity (we always have more data). The rise of cloud and self-service solutions enabling business users to do more by themself put pressure on the IT department to catch up Spreadsheets don’t scale and don’t automate well. Developers and data engineers cannot keep pace with the increasing volume of requests for custom scripts.
Over the last few years, we have seen a lot of advocating for the rise of the Data Scientist: the sexiest job of the 21st century. A Data Scientist is someone who can master
- Data engineering: to store, process, and transform data at scale without corrupting them;
- Statistical modelling: to build predictive and analytical models without introducing bias and statistical errors; and
- Domain expertise: so the results of the model make sense in the real world.
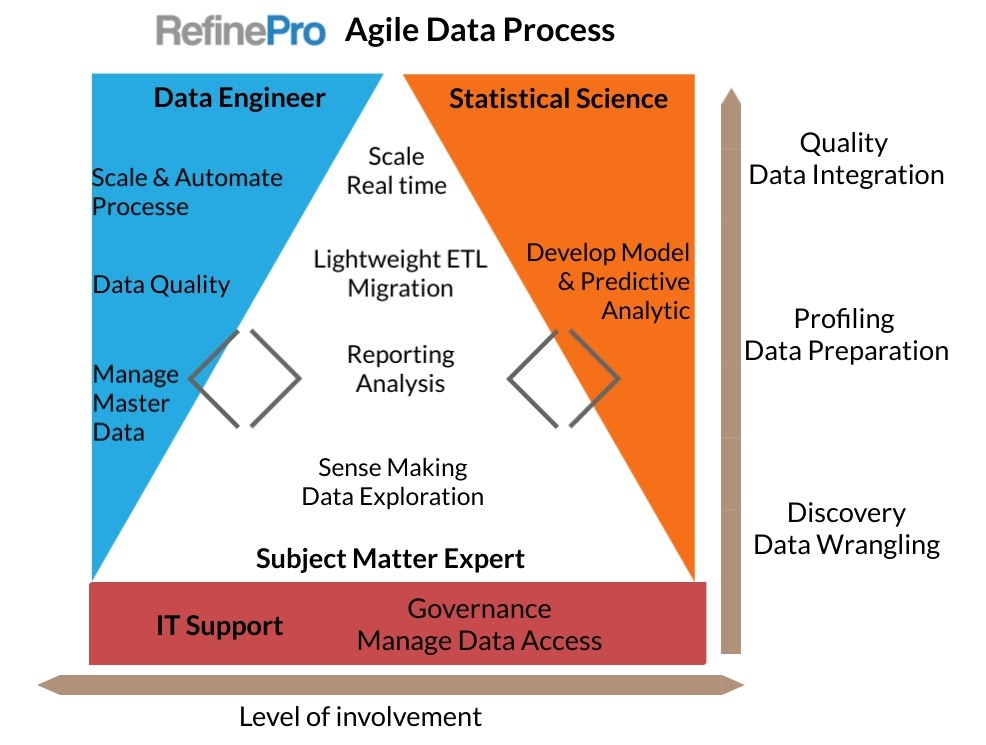
Data scientists are hard to find and don’t scale. Instead of looking for unicorns, we envision a different approach: empowering the subject expert and providing him tools to succeed in his data project.
A new model placing the business at the center
In this iterative data processing model, the subject expert or business user leads the way from data exploration to in-depth analytic and system migration and synchronization. As the analyst progresses in his journey, he/she receives extra support from data engineers and the statistic modelling team.
Data engineers and statisticians will focus on their core skills. The data engineer will offer help for everything related to Master Data Management (MDM) and how to keep a single record of truth, techniques to ensure high data quality, and tackle transformation challenges and processing data at scale.
On the other side, the statisticians will make available analytical models and machine learning processes for users to leverage in their projects.
Let’s take a concrete example:
Joe is a marketing analyst and he is searching for new market opportunities. To build his analysis, he starts collecting different data sources from the public census, earlier market surveys, plus customer and prospect lists from his CRM. In this discovery and wrangling phase, Joe places each data in the context of his research. The Data Engineer and statistical team give little support at this stage, as Joe is the best person to make sense of the data using his domain expertise.
As Joe learns from his exploration and selected data sources, use cases and patterns start to emerge, and he identifies five potential markets. It is now time to prepare a report showing the different opportunities in his favorite business intelligence tool. Joe needs to profile and prepare the data, reformat and normalize them, and then blend some sources. He reconcile the survey participant results against the internal customer list to see who the organization is already in contact with. Finally, Joe also wants to enrich his data using a predictive model defined three months ago for a similar market by the statistic team. Once Joe identifies the key leads for each new market, he wants to add them to the CRM system. To do this small migration, he needs to make sure his data match the CRM data schema.
From the five market opportunities identified by Joe, the organization decided to invest in two of them. It is now time to scale. Joe works to match new leads with internal master data and enrich them with the predictive model in real-time before adding them to the CRM system. Joe builds a strong business case for the organization to commit resources to these two key markets and to have data engineers and statisticians integrate the different pieces.
Joe’s story isn’t limited to someone in the marketing role. Anyone working with data, from librarians, researchers, data journalists, or consultants across industries, face similar issues.
- They are subject matter experts in their domain and need to process an increasing amount of data as part of their job.
- They know how to process and normalize data in a spreadsheet application, but don’t have the time to learn coding skills to scale those techniques.
- They see the potential of machine learning, predictive model, and existing analytics services, however, those are often available via API only and require coding skills.
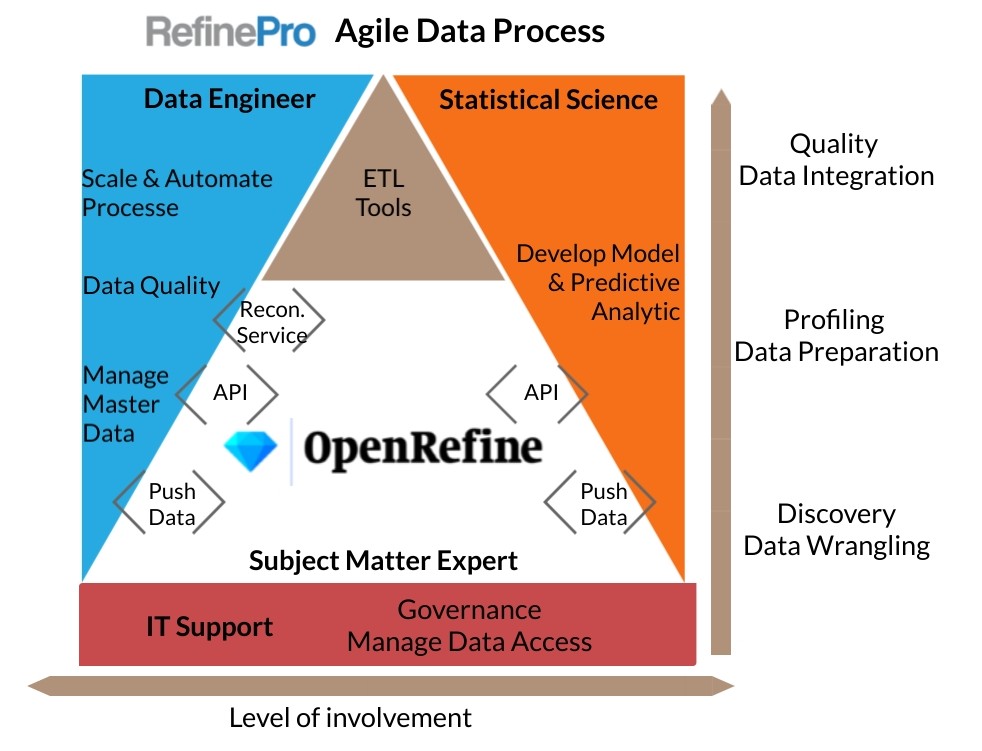
OpenRefine the platform to support iterative data
OpenRefine is the platform where domain expertise, data connection, and predictive models meet.OpenRefine’s point and click interface let subject matter experts take the lead on the project while providing seamless access to data engineer and statistician support. Thanks to OpenRefine architecture and functionality, users can
- Ensure data quality using OpenRefine clustering and profiling features;
- Reconcile data against a known master data set using the reconciliation functionality;
- Align data against a defined schema (see the work done by the GOKb team);
- access machine learning and predictive and statistic models via API (see the NER extension for example); and
- Push and pull data from data repositories and applications (see the Google Doc integration).
As the data project moves up in the process, data engineers and statisticians get more and more involved. Some projects will reach a point where OpenRefine cannot scale due to the data set size or the need for real-time processing. This is where data quality and integration tools like ETL are the best suited to this job. In OpenRefine, the user develops a strong case, and even a prototype, laying out the requirements for a data engineer to invest his time.
We have the experts to make it happen.