How to divide and conquer your data project for success
Martin Magdinier | 17 May 2020

Data extraction is now one of the most efficient ways for companies to stay up to date with current events and trends, but also to position themselves in their field. But for a lot of small entrepreneurs and even larger companies, the implementation of data extraction projects presents new challenges: How should these processes be implemented, and by whom?
Web Scraping is known as the process by which data is extracted from different sources and then transformed into usable information. As such, a huge part of any web scraping project relies on a strong Extraction, Transformation, and Loading process, known as ETL. But building a solid ETL architecture for your web scraping requires a lot of technical know-how, combined with the knowledge necessary to adapt these “easy-to-use” tools to your specific needs. Most importantly, your project will also rely on many other crucial processes, including data quality management and administrative procedures.
In this article, we explain why all your different data extraction processes should be decoupled for a more seamless workflow. That might sound counterintuitive… But the idea is as old as the world: divide and conquer (even algorithms understand). Divide your script, divide your task, find solution to sub-problems instead of a major crash, and get reliable end results, without draining your economic and human resources.
1. WHAT IS ETL?
During ETL, data is being copied from pre-defined sources before reaching you in a format that makes it usable. An ETL developer can help you build an architecture that will support the ETL process of your project.
Why an “ETL” developer? A developer creating a robust data transformation process work at the crossroad of different fields and execute functions as diversified as database analysis, system integration, and data transformation development. He or she must ensure that every aspect of the data life cycle has been addressed to ensure its operability and maintainability.
2. THE EXTRACTION, TRANSFORMATION, AND LOADING BEHIND ETL
The three main steps of ETL will come as no surprise: extraction, transformation, and loading. But as one might suspect, each of these steps hides a lot of sub-steps that need to be considered. Data going through an ETL process will undergo different stages in its journey. We will now examine how these stages integrate within the three main steps of ETL. And keep in mind our “divide to conquer” motto: every step of your ETL as its own logic and should be considered separately.
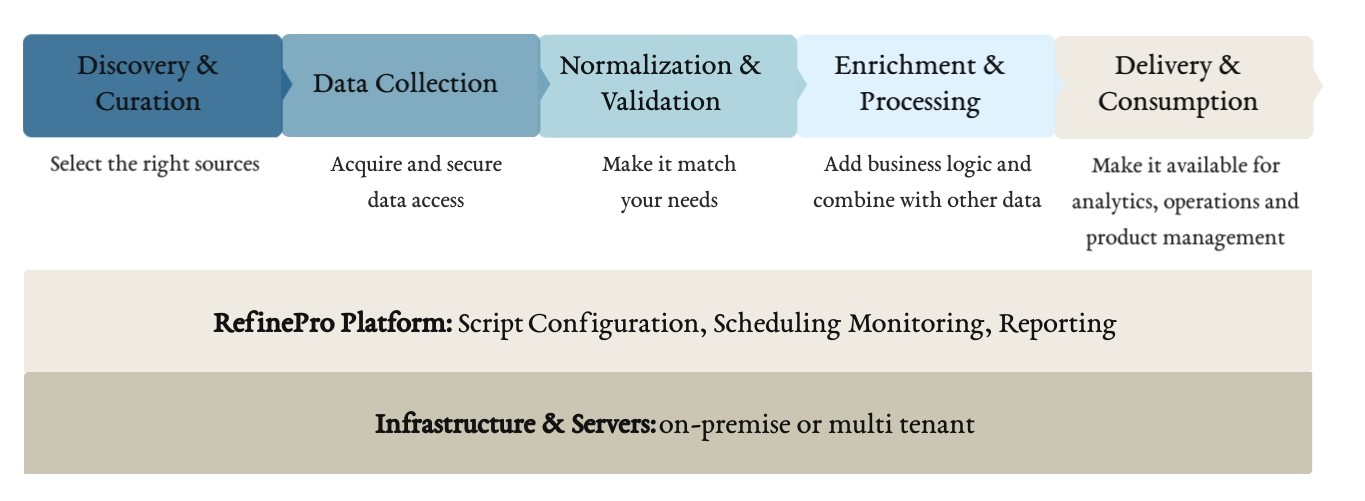
2.1 Discovery and curation
Before you sit down with your developer and start coding, you must define precisely what sources you want to extract your data from and how you’re going to document all the relevant information (including the owner, the availability, the updates, etc.). At the end,
- You know who published your data, when, and how;
- You know what your data looks like (its size, format, relations to other data), and;
- You have a map of your data, from the source to your database.
Once discovery and curation are done, you can now jump on step two, data collection.
2.2 Data collection (Extract)
At this substep, your focus should be on getting to data out from its original format. You will need to select the right data extraction technology, whether it is to get data from another database, XLS files, a website or a PDF document. Once it has been extracted, data can now be moved to a landing database in your dedicated data transformation environment. It’s from this new environment, entirely under your control, that you can start reviewing and troubleshooting the data.
2.3 Normalization and validation (Transform)
Now that you’ve extracted your data, you need to transform it. During the normalization and validation, the messy data you obtained is being prepared to match the format of your target system, whether it’s a data warehouse or your eCommerce website. Before you start developing a transformation process, though, make sure you know what the best practices are and which ones you need to implement (and ignore).
But remember! Divide to conquer: data extraction (step 1) should be decoupled from the transformation (step 2). Why?
- It makes debugging and restartability easier by segmenting more precisely the journey of your data (see our article on data quality).
- It gives your (ETL) developer the possibility to select the best tool for each job. This way, your web scraper will do its job of scraping (which is already a complex job in itself) and your data cleansing tool will do its job of cleaning.
2.4 Enrichment and processing (Transform)
Enrichment and processing steps add value to your data by connecting it with other datasets, such as your own proprietary data (like your customer or product information), for example, or other collected datasets. At this stage, you add your business logic, your secret sauce, so that your team can read and make sense of the data. By adding your business logic to messy data, you give yourself the possibility to develop real business intelligence. And that’s when data extraction really becomes interesting.
Again, decoupling is important here. You should have a single processing script for all your data sources. It is a good time to create historical values by comparing records, a process often referred to as the six slow changing dimensions (mainly the ability to keep track of unpredictable changes). Building historical information from extracted data gives you an edge (if not an unfair advantage) in understanding your market and industry. You could, for example, track the price of an item over time to predict when it will be on sale or out of stock.
2.5 Delivery and consumption (Load)
Your data is now ready to be used. But in order to do so, you need to move it from your external database into a data warehouse available to your team. During this last substep, we read data from the staging or landing table and insert it into your system. We can push it into a warehouse, upload it directly into your operational system (like an eCommerce website), or make it available to your organization via a custom API.
2.6 Administration, making it all work together
It’s the long-forgotten process, but still a crucial one. The administration will orchestrate the many processes we previously covered. A well-administered project will manage depencies between steps, and make sure everything happens in the right order. Your main tools, including your web scraper, will need to be well scheduled, maintained, and monitored. It will also be crucial that you implement practices such as logging, code management, configuration, and project management.
Data discovery and curation, data collection, normalization and validation, enrichment and processing, delivery and consumption, and administration: these are the multiple layers you find when your start scratching the varnish of a data extraction project. They all contribute to the overall stability, but their uniqueness is also what makes the whole structure stronger. With a well-built architecture, the whole system is not affected if one layer is posing a problem or needs to be upgraded for any technical or business reason.
3. AND WITH THAT
Obviously, a complex process such as this can’t be built in a day. It takes trial and error to select the best technology and processes, and also to confirm that you can build value from the data. Every data project has its own specificities. Your organization may have a short-term, extremely precise need for data extraction, but most companies want data that support their business strategy, one they can rely on in the long term to make important decisions. This is why we recommend following an agile data transformation process. We suggest developing complex data products by starting small with a couple of sources before scaling it to a robust business-wide data factory.
Over the years, we’ve built a strong experience in developing and managing these different processes. Our clients rely on us to manage every aspect, layer, and step of their data collection project so they can focus on building lasting insight and product. By doing so, they know they’re paying the right price for their data, and that they’re not overwhelming their development team.
Depending on your team know-how level, your needs will also change. We can deliver custom training for your team before they throw themselves into web scraping, help you build your project from scratch, or even assist you after its implementation. We offer training and mentoring as well as team augmentation, and data-first application development.
We have the experts to make it happen.