PDF extraction - Everything you need to know
Martin Magdinier | 18 May 2020

Our team here at RefinePro has a deep experience doing research and development in data processing and automation. And PDF extraction is one of the many services we offer.
But before we go into too much detail … why exactly do people need PDF extraction for?
Portable Document Format, or PDF, is a standardized file format. It allows users to distribute read-only documents that will present the same text and images independently of the hardware, software, or operating system used to open it (Mac, Windows, Linux, iPhone, Android, and others). PDF documents may contain a wide variety of information other than text and graphics, such as interactive elements (annotations and editable fields), structural elements, media, and various other content formats.
In today’s work environment, PDF is often the go-to solution for exchanging business data. Suppliers, for example, mostly prefer PDF to create their price lists and catalogues and to exchange invoices, purchase orders, reports, etc. So, whether you’re trying to gather a larger volume of data on a specific subject in your field of research or just trying to extract a list of items and prices for your eCommerce website, you need to find a way to convert information contained in PDF documents into usable structured data.
And let’s be honest, nobody wants to (or can!) go through doze or even hundreds of documents manually.
PDF documents are easy to read for humans, but they rarely contain any machine-readable data. Their format varies considerably from one file to another, depending on how it was generated. If you’re lucky, the document you’re extracting your data from is in text format, with numbers organized neatly in tables. But if you’re not lucky, the information is embedded in an image. In that case, you’ll need to use Optical Character Recognition (OCR) to help you get the data.
Accessing a massive amount of information stored in PDFs and converting it can then be a burdensome task. Luckily, PDF data extraction offers solutions to automate this task and automatically convert messy information into structured and usable data. And PDF extraction projects are no news for us. We invested in some of the proven technologies, and we are always testing out new software to make sure we help you build the data extraction project you need to meet your goals.
1. PDF EXTRACTION: HOW?
1.1 THE RIGHT TOOL FOR YOUR PROJECT
There are a lot of different systems out there to help you set a solid PDF extraction project. For business analysts, it’s often easier to go with “What You See Is What You Get” interfaces (WYSIWYG) like DocParser. These systems tend to be more expensive, but they are easy to use and set, and they work well with high volume of easy cases. For entry-level programmers, some solutions offer more flexibility and low code complexity, which makes it easier to support exceptions for complex files. However, they still require programming knowledge and expertise on data extraction project as a whole. They usually run on JAVA or Python.
The advantage of working with a partner like RefinePro is that thanks to our years of experience, we can help you select the technology that will best answer your requirements. We listed the four categories you should keep in mind.
1.2 ASSESSING YOUR NEEDS
Your business and legal requirements: You should ask yourself:
- Are you working with sensitive data? What privacy laws do you need to comply with?
- Do you want to use non-open source technology?
- What level of dependency do you want or can have on a service or technology provider?
The connectivity to your systems: This includes the method used to send and receive the PDFs with your systems (e.g. via an API, a database connection, or other) and if you want to process files in batch or on-demand as they are collected?
The volume of data: including how many are your processing per day? How many different layouts? What are the data validation rules (schema, business rules, etc.); and what happens when the validation job rejects data (the review process).
Your Resources: Who will monitor your PDF extraction project? What type of skills (and training) do they need? What kind of medium- and long-term support do you need?
2. REFINEPRO’S PDF EXTRACTION SUBSYSTEMS
Over the years, we have developed an extraction architecture that relies on a set of best practices and proven engineered patterns. We recommend decoupling your steps to make troubleshooting easier. PDF extraction should follow four steps: data collection, data normalization, data validation, and delivery.
These steps are part of an architecture in which ingestion and normalization of each PDF document are divided into three subsystems.
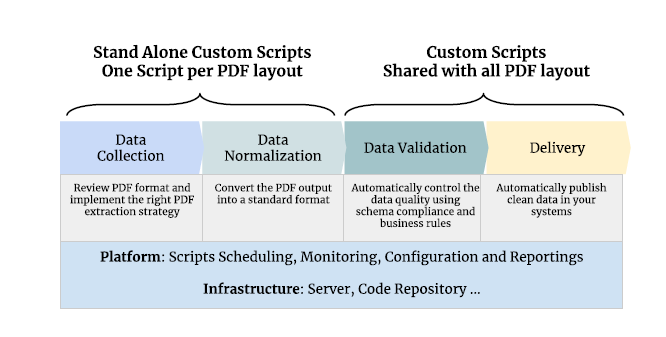
2.1 Subsystem One. Collection and Normalization.
In the first part, we bring together collection and normalization. All the different formats of data collected are being morphed into a standard schema, which is the set of validation rules you implemented to define what a “good” data is. To do so, the developer writes one PDF extraction and one normalization script per PDF layout. In other words, different scripts are used depending on the outlines, style, and logical component content of the PDF. This way, one script will extract data from documents matching the same layout—the same logical structure—to then transform it in a usable format for your team.
In this script, the developer will add all the exceptions related to a specific PDF layout so that each file format can be processed independently. This way, if one script returns an error, it only affects one layout and not the entire project, making troubleshooting easier.
For the normalization step, more specifically, OpenRefine is a great tool if you want to build a fully WYSIWYG solution (something we can help you with). On the other hand, Talend Open Studio, is perfect if you want to outsource the work to entry-level programmers. We can also train your team and help you launch your first project!
2.2 Subsystem Two. Validation and delivery (or the delivery of quality data)
During the second part, which includes validation and delivery, we leverage a unified schema. We only need one validation and one delivery script for all PDF layout. The data is being validated using the schema to ensure compliance with your business rules before it is delivered into your system.
During validation, we define and document the schema, namely the elements that make a “good” data. As such, a validation error occurs when an extracted data doesn’t pass the validation rules established for the project. This corruption can come from a bug in the workflow, or changes in the data sources.
This step is particularly important. When we develop a PDF extraction project script, one of the priorities is to create a validation script to ensure we do not over-engineered data quality. We need to ensure that the validation steps fail as early as possible to avoid corrupting downstream systems.
2.3 Subsystem Three. Scheduling, Monitoring, and Maintaining
The third part is the use of infrastructure or platform to execute, schedule, configure, and monitor the scripts themselves to ensure they keep delivering reliable data. Most importantly, also, data quality (article 3) will need to be monitored thoroughly.
WHAT ABOUT AI?
Artificial Intelligence is the new kid on the block. Everyone knows it, everybody wants to use it, many people claim to have mastered it, but few people actually offer it. In PDF extraction, more specifically, we have seen a lot of promising development, but we’re not there yet. AI can be used for very narrow use cases. Instead of trying to find the next shiny object, we recommend sticking to well-proven and tested solutions that will help you get the results you’re looking for. Be sure, however, that our team is keeping a close eye on all the new technologies out there. Don’t hesitate to contact us curious@refinepro.com if you’d like an independent assessment on a specific software.
AND WITH THAT
Here at RefinePro, we provide data strategy, system architecture, implementation, and outsourcing services to help organizations scale and automate data acquisition and transformation workflows. Whether you decide to work with us, with another service provider, or even on your own, you’ll need to make sure to select the right tools (and not just the PDF extracting tool: database, servers, data processing framework, etc.) and set up your processes to meet your data quality requirements while minimizing the maintenance efforts.
For years, we have helped clients define what system and process to put in place to ensure their needs are answered in the most time- and cost-efficient manner. So, before you throw yourself on Google or your in-house expertise to develop a complex data extraction project, contact us!
We have the experts to make it happen.